对于项目中客户提供的相对稍大的数据,开发时,本地验证测试很流畅,但是 APP 打包部署到服务端后,受到网速的限制,稍大的文件从网络请求耗时会挺长,会明显影响加载速度,导致体验变差。
技术方案: #
indexedDB #
indexedDB 是一种底层 API,用于在客户端存储大量的结构化数据(也包括文件/二进制大型对象(blobs))。该 API 使用索引实现对数据的高性能搜索 。
indexedDB 相对于 localStorage来说,操作会略复杂一些,有一个开源库 localForage ,可以帮我们简化对indexedDB的操作,有了它,我们可以像使用 localStorage 那样来操作indexedDB 。
// 通过 localStorage 设置值
localStorage.setItem("key", JSON.stringify("value"));
doSomethingElse();
// 通过 localForage 完成同样功能
localforage.setItem("key", "value").then(doSomethingElse);
// localForage 同样支持回调函数
localforage.setItem("key", "value", doSomethingElse);
另外,还有重要的一点,indexedDB 可以在 Service worker 中使用。这样我们就可以用Service worker来将数据写入到indexedDB中。
我们可以在浏览器查看客户端存储限额:
在浏览器打开开发者工具,打开Application-Storage,如图我的电脑显示可用约193Gb,对于项目上的常用数据来说,完全足够了。
Service worker #
Service worker 运行在 worker 上下文,因此它不能访问 DOM。相对于驱动应用的主 JavaScript 线程,它运行在其他线程中,所以不会造成阻塞。它设计为完全异步,同步 API(如XHR和localStorage)不能在 service worker 中使用。
Service worker 功能非常强大,它采用 JavaScript 控制关联的页面或者网站,拦截并修改访问和资源请求,细粒度地缓存资源。你可以完全控制应用在特定情形(最常见的情形是网络不可用)下的表现。
需要注意的是:Service workers只能用在HTTPS或者本地的网站中,对于没有 HTTPS 的网络环境,需要考虑不可用的时候如何存储数据。
我们在这里只用到它的很小一部分的功能: 在 APP 首次运行时,注册一个Service worker, 在后台从服务端下载需要的数据文件,并将其存储到indexedDB中。
功能介绍完毕,我们开始使用试一试~
实际使用 #
初始化项目 #
使用命令行初始化 #
略
配置 service-worker.js #
在client目录下新建servier-worker.js文件,暂时先留空。
然后在client/index.tsx中新增如下内容
// 注册 service-worker
// 每次客户端的service worker 有更新,会触发安装事件
if ("serviceWorker" in navigator) {
window.addEventListener("load", () => {
navigator.serviceWorker.register("./service-worker.js");
});
}
在Service worker中, JavaScript modules 是不能工作的,意味着我们无法直接通过 es modules 导入项目中安装的三方包。
Service worker提供了 importScript 的方式来引用第三方包,使用方法如下,但是用起来有点不方便。
importScripts("foo.js");
使用谷歌开发的Workbox并配合webpack插件可以解决上面的问题,它可以把我们用esmodule引用的模块编译到一个service-worker文件中。
Workbox 是一组库,可以帮助我们编写、管理
Service worker,同时通过CacheStorageAPI,可以帮助我们管理缓存站点的文件。让你控制如何在您的网站上使用的资产(HTML,CSS,JS,图片等)从网络或高速缓存的要求,甚至允许你离线时,返回缓存内容!使用 Workbox,您可以使用生产就绪的代码快速设置和管理两者,以及更多。
安装 workbox #
yarn add --dev workbox-webpack-plugin
在 webpack.config.js中添加如下配置
const WorkboxPlugin = require("workbox-webpack-plugin");
// 在generateConfig后添加
webpackConfig.plugins.push(
new WorkboxPlugin.InjectManifest({
swSrc: "./client/service-worker.js",
// 10mb
maximumFileSizeToCacheInBytes: 1024 * 1024 * 1024,
exclude: [
/\.map$/,
/manifest$/,
/service-worker\.js$/,
// esri目录下的资源太多,700+文件,不做预先缓存
/\/esri\/.*$/,
// 排除如下的arcgis_core相关的js,约30+
// default-node_modules_arcgis_core_chunks_quickselect_js-node_modules_arcgis_core_layers_graphi-f764e3.js
// default-node_modules_arcgis_core_core_sql_WhereClause_js.js
/arcgis_core+_(\S)*.js/,
//关键的文件缓存到indexedDB,不通过workbox缓存
/\.(bin|glb|gltf|json|geojson)$/,
// 数据的配置文件,不做缓存
/config\.json$/,
//排除app打包生成的js
/app/,
/vendors/,
/runtime/,
],
})
);
修改 service-worker.js内容如下
import { precacheAndRoute } from "workbox-precaching";
// 预缓存站点所有资源
precacheAndRoute(self.__WB_MANIFEST);
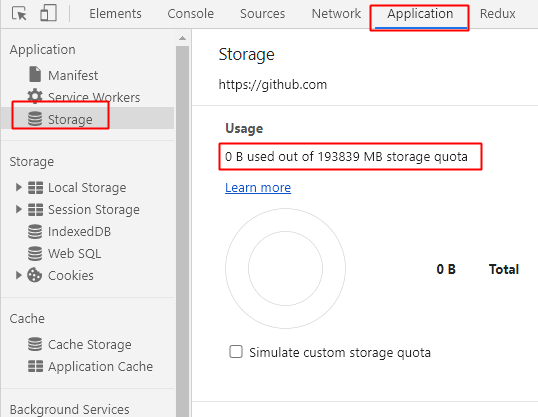
self.addEventListener("install", function (evt) {
console.log("The service worker is being install.");
});
self.addEventListener("fetch", function (evt) {
console.log("The service worker is being fetch.");
});
self.addEventListener("activate", function (evt) {
console.log("The service worker is being activate.");
});
运行 #
打开控制台, 我们可以看到配置已经生效了,同时 workbox 也会帮我们缓存站点的符合规则的资源
与 indexedDB 交互 #
我们想要在首次打开站点时,就把我们想要缓存的数据保存下来,所有需要我们在service-worker.js的install事件中,从服务端获取资源,存储到本地。
service-worker.js中添加如下代码,在evt.waitUntil中调用了preCache()方法,在install 事件触发后,直到precache执行完成,install 事件才会结束,下一步的activate事件才会触发。
self.addEventListener("install", function (evt) {
console.log("The service worker is being install.");
// 等待数据缓存完成
evt.waitUntil(precache());
});
我们缓存数据的的逻辑就放在precache函数中。
准备数据和配置文件 #
在client目录下新建assets文件夹,并新建config.json文件,用于管理我们要在indexedDB存放的数据,同时,放一份测试数据到assets目录中
根据测试数据的名字,config.json内容如下
[
{
"url": "./assets/poi5W.json",
"name": "poi5W",
"format": "json",
"version": "v1"
}
]
url: 网络请求的地址
name: 文件名称
format: 文件格式,因为缓存的数据不一定都是json,所以单独拿出来方便配置,数据类型可能有多种,按需再补充,目前有 json|arrayBuffer|blob|text
version: 版本
缓存数据逻辑编写 #
安装三方库,localforage 上文已有介绍。geobuf 可以把 json文件压缩为二进制的pbf文件,大大减小文件体积,如果服务端的数据是pbf文件,我们需要在service worker中将二进制的 pbf 文件 decode回 json。
yarn add localforage geobuf
service-worker.js添加如下代码
import localforage from "localforage";
import geobuf from "geobuf";
import Pbf from "pbf";
导入上一步中的config.json
import dataItems from "./assets/config.json";
这里有一个关键的点,当我们的数据需要更新的时候,service worker是感知不到的,所以在存储数据时,用 json中的 name_version 来组合作为 indexedDB保存数据的key,上面数据存储的key为poi5W_v1。数据有更新,修改version版本就可以。
因为我们将
config.json导入到了service-worker.js中,每当浏览器检测到service-worker.js有变化时,会重新触发install事件,配合下一步的逻辑,就可以做到配置有更新就会下载到本地。
下面编写关键的缓存逻辑
// 数据可能有不同格式,fetch的时候responseType需要修改
const DATATYPE = {
JSON: "json", //json
PBF: "pbf", // arraybuffer
GLB: "glb", // blob
CSV: "csv", // text
};
// 检查当前数据在indexedDB中是否已经存在
const checkDataExist = async (fileKey) => {
const isExists = await localforage
.keys()
.then((res) => res.includes(fileKey));
console.log("isExists :>> ", fileKey, isExists);
return isExists;
};
// 上文说到的 preache 函数
const precache = async () => {
// 要缓存的数据可能会不止有1份,并行处理
await Promise.all(
dataItems.map(async (dataItem) => {
const fileKey = dataItem.name + "_" + dataItem.version;
const isExist = await checkDataExist(fileKey);
if (!isExist) {
const result = await fetch(dataItem.url).then((res) => {
switch (dataItem.format) {
case DATATYPE.PBF:
return res.arrayBuffer();
case DATATYPE.JSON:
return res.json();
case DATATYPE.GLB:
return res.blob();
case DATATYPE.CSV:
return res.text();
default:
return res.json();
}
});
// 压缩过的json需要decode回json文件
if (dataItem.format === DATATYPE.PBF) {
const geojson = geobuf.decode(new Pbf(result));
// 存入 indexedDB
localforage.setItem(fileKey, geojson);
} else {
// 存入 indexedDB
localforage.setItem(fileKey, result);
}
console.log("writing data to indexedDB :>> ", fileKey);
} else {
console.log("already exists in indexedDB :>> ", fileKey);
}
})
);
};
验证 #
运行并打开控制台,可以看到我们的数据已经成功存储到indexedDB中了
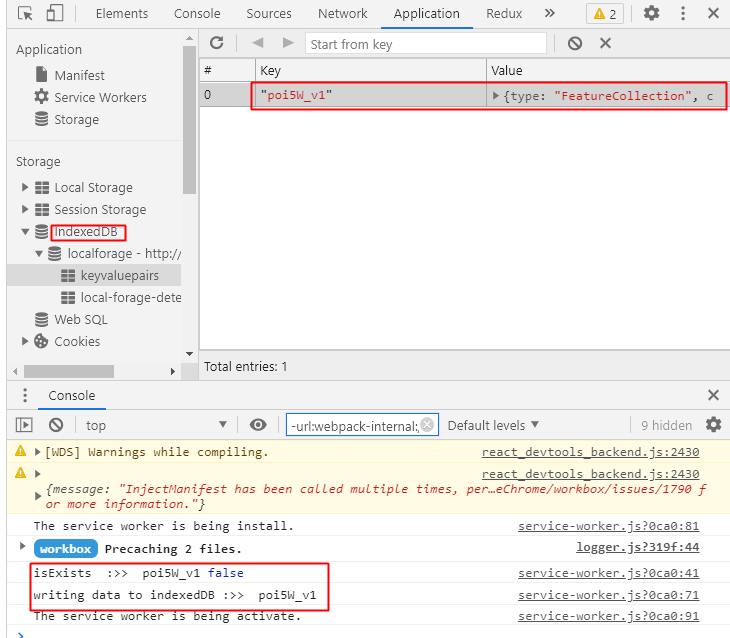
使用数据 #
localforage.getItem("poi5W_v1").then(function (data) {
// data
});
效果 #